最近呢,总是有人反馈公司的一个系统页面反应太慢,一个列表展示,竟然需要二三十秒,我上去点了点,发现没二三十秒那么夸张,但是也是够慢了,龟速,直接影响工作效率啊。所以从这星期开始,我便硬着头皮上优化系统了。
这个系统使用MVC3+Easy UI做的,数据库用的是SQL Server 2012。优化呢,首先就是定位原因,刚开始呢,只能按传统方法来,想想瓶颈在哪,网络传输,程序响应和页面渲染,磁盘IO。前两个我是没法控制了,只有想想最后的法子了,从数据库入手了。
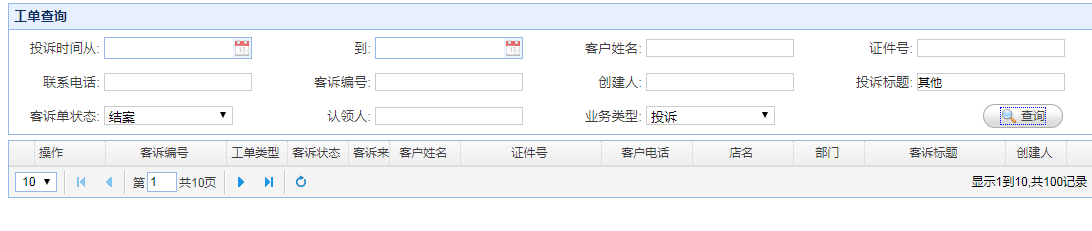
上图就是执行页面很缓慢的界面。首先监控到其sql语句,因为手里有源代码,直接就用程序调试获取了,不用 SQL Server Profiler。拿到sql语句后,就开始对sql进行分析,看看哪里能进行优化。一条真理:尽可能的避免全表扫描。
SELECT TOP 10 * FROM ( SELECT ROW_NUMBER() OVER (ORDER BY CREATEDATE DESC) AS RowNumber,b.* FROM ( SELECT WO.WorkOrderCode,WO.WorkOrderType,WO.Status,WO.CustName,WO.CustTel1,WO.CustTel2,WO.CustIdentityNo,WO.CardId,WO.CustSex,WO.CustAge,WO.CustBirthday, WO.IsMember,WO.AccountLevel,WO.MemberDate,WO.AccountScore,WO.DestTarget,WO.DestTargetDesc,WO.Source,WO.ToType,WO.Dept,WO.HotelId,WO.HotelName, WO.HotelCreateDate,WO.HotelType,WO.HotelBrand,WO.HotelTel,WO.HotelBigArea,WO.HotelArea,WO.HotelCityGroup,'' AS HotelCity,WO.Title,WO.SelectTitle,WO.Content,WO.IsAccept,WO.CompensateDept, WO.CompensateAmountType,WO.CompensateAmount,WO.ReferDept,WO.ResponsiblePerson,W2.Attribute3 AS ResponsiblePersonName,WO.ResponsibleDate,WO.ClosePerson, WO.CloseDate,WO.CatePerson,WO.CateDate,WO.ScorePerson,WO.ScoreDate,WO.CreateUser,WO.CreateDate,WO.UpdateUser,WO.UpdateDate,W1.Attribute3 AS UserName FROM WorkOrder WO WITH (NOLOCK) LEFT JOIN WSCUser W1 ON WO.CreateUser=W1.UserID LEFT JOIN WSCUser W2 ON WO.ResponsiblePerson=W2.UserID WHERE 1=1 AND (WO.Title LIKE '%其他%' OR WO.SelectTitle LIKE '%其他%') AND WO.CreateDate BETWEEN '2017-09-03 00:00:00' AND '2017-09-30 23:59:59' AND WO.STATUS=3 AND W2.Attribute3 ='张三' AND WO.WorkOrderType='T' AND WO.IsDelete=0 ) b ) a WHERE RowNumber > 0 order by rownumber
1. 从里往外看吧,最里层的子查询,是3个表的左连接查询,这个地方可以采用的方案有两种:
①在连接字段WO表的字段CreateUser上建立索引,②把这个联合查询做成视图(此法效果不好)。
2.之后再看where后边,
①Title中用了like查询,可以改成=,但是标题那个地方要求有模糊搜索功能(此法不可取)。
②对于status(三种状态),workordertype(四种状态),IsDelete(两种状态)这些建立索引,但是索引建立之后,效果很差,因为对于这种区别度很小的字 段,建立索引后,查询时还会增加 KeyLookup(标签查找 ),性能并不一定会提升(此法效果不好)。
③对于这种条件不固定的查询,基本上可以把多列索引这种方案给排除了,查询出来二三十个字段,也可以把覆盖索引给排除了(此法不可取)。
④最后只能选择在CreateDate字段上建立索引了(此法可取)。
3.对于分页算法,分页算法有好几种,经过考虑,这种用ROW_NUMBER()的方法效率还可以。所以说换一个分页算法,需要改大量程序代码,这种方法也是不可取的。
综上所述,选择的方法只有是在CreateDate上建立索引了。
④之后还有一部操作,如下图所失,将索引重新组织一下,因为时间长了,碎片比较多。

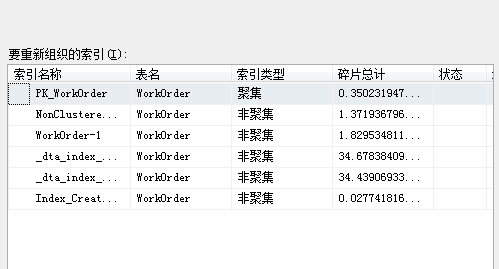
注意:进行重新组织索引时,一定不要在程序访问量大时进行,因为会造成锁表,系统直接无法使用。这个过程是很有风险的,数据量太大,执行也是需要一定时间的。
本来也为好了,可是故事未完待续,我把这段sql在数据库中执行,发现用时只有0.3s左右,但是系统中能看到结果,还需要1.4s左右。我刚开始还以为是系统代码太烂,EasyUI框架太重的原因。又调试了一会儿才发现是,程序执行了分页语句之后,又执行了一段算数据总数的sql,原来是count()惹的货。

select count(*) from ( SELECT WO.WorkOrderCode,WO.WorkOrderType,WO.Status,WO.CustName,WO.CustTel1,WO.CustTel2,WO.CustIdentityNo,WO.CardId,WO.CustSex,WO.CustAge,WO.CustBirthday, WO.IsMember,WO.AccountLevel,WO.MemberDate,WO.AccountScore,WO.DestTarget,WO.DestTargetDesc,WO.Source,WO.ToType,WO.Dept,WO.HotelId,WO.HotelName, WO.HotelCreateDate,WO.HotelType,WO.HotelBrand,WO.HotelTel,WO.HotelBigArea,WO.HotelArea,WO.HotelCityGroup,'' AS HotelCity,WO.Title,WO.SelectTitle,WO.Content,WO.IsAccept,WO.CompensateDept, WO.CompensateAmountType,WO.CompensateAmount,WO.ReferDept,WO.ResponsiblePerson,W2.Attribute3 AS ResponsiblePersonName,WO.ResponsibleDate,WO.ClosePerson, WO.CloseDate,WO.CatePerson,WO.CateDate,WO.ScorePerson,WO.ScoreDate,WO.CreateUser,WO.CreateDate,WO.UpdateUser,WO.UpdateDate,W1.Attribute3 AS UserName FROM WorkOrder WO WITH (NOLOCK) LEFT JOIN WSCUser W1 ON WO.CreateUser=W1.UserID LEFT JOIN WSCUser W2 ON WO.ResponsiblePerson=W2.UserID WHERE 1=1 AND (WO.Title LIKE '%其他%' OR WO.SelectTitle LIKE '%其他%') AND WO.CreateDate BETWEEN '2016-05-03 00:00:00' AND '2017-09-30 23:59:59' AND WO.STATUS=3 AND WO.WorkOrderType='T' AND WO.IsDelete=0 ) a
上图就是算总数据量的语句,这个语句的优化可以这样。
1.count(*)可以改成count(WorkOrderCode),WorkOrderCode是WorkOrder的主键,经过测试执行效率要快于count(*)。--详情请见
2.将查询字段全部去掉。
优化完成之后,语句变成这样。
SELECT count(WorkOrderCode) FROM WorkOrder WO WITH (NOLOCK) LEFT JOIN WSCUser W1 ON WO.CreateUser=W1.UserID LEFT JOIN WSCUser W2 ON WO.ResponsiblePerson=W2.UserID WHERE 1=1 AND (WO.Title LIKE '%其他%' OR WO.SelectTitle LIKE '%其他%') AND WO.CreateDate BETWEEN '2016-05-03 00:00:00' AND '2017-09-30 23:59:59' AND WO.STATUS=3 AND WO.WorkOrderType='T' AND WO.IsDelete=0
到这里,优化算是正式结束了,搞了三四天。在这过程中也对数据库的索引,语句优化有了更加深刻的认识。当然有些也颠覆了我以前看到理论,如联合查询建成视图后,查视图效率会提升,但是我做的实验并非如此,视图效率不如联合索引。
抛开技术上的因素,还有很多业务上的需要考虑,像刚开始的那个查询条件表单,有些选项可能就很少使用,但刚开始我也考虑了很多种情况,后来,跟客服人员沟通,发现他们有些选项就不怎么用,之后我按照他们给的经常使用的筛选条件,进行优化,也就不那么盲目了,问题也好处理了。通过这件事呢,总结出两条哲理:“干活儿不由东,累死也误工”、“沟通很重要”。
世事洞明皆学问 人情练达即文章,技术始终是要为人而服务的,所以不要为了技术而技术。